拿下大厂实习
OFFER
[应届/在校]
一站式解决:方向规划 | 简历重塑 | 实战项目 | 硬核 Mock
预约资深顾问老师1v1评估
Research Intern - AI Safety & Reliability for LLM Systems
发布于 2026-02-12
员工人数:221,000 (2022)
行业分类:Information technology
Overview
Research Internships at Microsoft provide a dynamic environment for research careers with a network of world-class research labs led by globally-recognized scientists and engineers, who pursue innovation in a range of scientific.
很多同学的简历打开只看到:
“想写项目,但作业太简单不敢放;投了几十份,连面试都没收到......”
解法很简单:
先有一个定制实习项目
我们的项目,从第一天就按大厂岗位需求来设计
“你的项目不再是本地跑通的一个脚本,而是真正能对外展示的项目”
面试官看的不是你做过什么项目,而是你会什么
你的简历缺“一个定制化实习!”
“我该做什么项目?”先聊10分钟,明确你的下一步
我们不仅帮你简历“有内容可写”
更确保“写的项目,正好是面试官想看的”
很多同学的简历没过,不是能力不够,而是经历与岗位需求之间缺少精准匹配
-
想投递Backend,简历却全是简单的Web全栈demo,缺乏高并发处理、缓存设计、数据库优化或分布式系统的实战体现
-
想投递LLM,简历却没有ransformer架构、模型微调、RAG系统构建或LLM应用框架的任何实践,HR会直接判断你还没进入该方向
-
想投递Data Engineer,简历却全是分析报告和可视化图表,缺乏ETL Pipeline、Spark/Flink数据处理或数据仓库建模等经历
我们不做通用项目
只做与你目标岗位匹配的定制化实习
-
我们会先结合你的技术背景和优势,帮你明确最适合的求职方向
-
面试官最看重的是过往项目经历是否匹配岗位,我们为你定制完美匹配的真实实战项目
-
同方向大厂导师带你,最新技术栈,从0到1在生产环境中搭建,还原大厂真实开发流程
-
支持人事背调,确保项目经历都真实可查
你的导师
每天在一线做同样的事情
由大厂在职面试官直接带教
只打造面试官最想看的、与你目标岗位完美契合的真实项目经历
工业级实习项目
技术栈对口,源于真实生产需求,面试官一眼看中
Automated Evaluation Framework for Multi-Task LLMs
- Designed a unified LLM evaluation framework to benchmark models across summarization, QA, translation, and instruction-following tasks.
- Built evaluation harness using Datasets + Evaluate (HuggingFace), integrating metrics such as BLEU, ROUGE-L, Exact Match, and GPT-4-based ranking.
- Deployed a lightweight FastAPI service to trigger batch or single-inference evaluation runs on scheduled jobs or CI events.
- Enabled per-task, per-model, and per-checkpoint comparison using MLflow logging and interactive dashboard via Streamlit.
- Added prompt variation testing using temperature sweep and length penalty grid search, highlighting response instability across checkpoints.
- Supported multi-language eval with mBERT sentence similarity and reference-free reward model (G-Eval) for low-resource languages.
- Integrated open-source MT-Bench and TruthfulQA datasets for adversarial robustness assessment, visualized via radar plot metrics, reducing manual LLM eval effort by >70%.
Real-Time Log Aggregation and Monitoring System
- Led the migration of a log aggregation system from Kafka Stream to Flink, reducing log processing latency from under 15 seconds to 1 second and increasing throughput from 1 million to over 5 million messages per second, enabling faster analysis and reporting for critical applications.
- Refactored a framework-agnostic Dead Letter Queue (DLQ) library using Kafka and Prometheus, standardizing log failure formats and achieving a centralized log collection system with a failure detection rate exceeding 90%.
- Designed and implemented RESTful APIs powered by Elasticsearch to query and filter logs, reducing troubleshooting time by 40% per ticket for support engineers by streamlining the search for blocking events and DLQ topics.
- Implemented a real-time rule injection server with gRPC APIs, enabling dynamic injection of log filtering and processing rules into the log pipeline, facilitating on-the-fly log transformation without impacting system availability.
- Built a monitoring service using Kotlin, Spring Boot, and PostgreSQL to track pipeline errors and log failures, providing real-time notifications to support engineers, thereby reducing the average issue resolution time by over 30%.
- Created and validated 23 PromQL queries for a Grafana dashboard, integrating customer-facing APIs to enhance monitoring capabilities across over 100 system metrics, improving visibility into the system's health and performance.
- Partnered with cross-functional teams, including infrastructure and DevOps, to deploy the system using Terraform and ensure scalable and fault-tolerant operation, supporting rapid growth in log data volume.
- Organized knowledge-sharing sessions with engineering teams to onboard new services onto the log aggregation system and optimize troubleshooting workflows, fostering organization-wide adoption.
Multimodal User Representation for Personalized Video Recommendation
- Designed a multimodal user representation model combining short video embeddings, clickstream data, and text queries using transformer encoders.
- Integrated BERT, ResNet18, and GraphSAGE user graph encoders with joint optimization under cross modal contrastive loss and next item prediction objectives.
- Constructed 30-day session features across 4 modalities, processing 100K+ events/day using PySpark and Delta Lake on Databricks.
- Applied dynamic negative sampling and temporal attention masking to model sequential dependencies in watch behavior.
- Trained model with Horovod + PyTorch Lightning on 64 GPU cluster, achieving +7.2% Recall@50 vs. LSTM baseline.
- Deployed embeddings to real time recommendation ranking layer, integrating with Triton Inference Server and TensorRT optimization, reducing latency by 37%.
- Validated performance in online interleaving A/B test, improving video completion rate by 4.6% and cold start CTR by 5.8%.
- Conducted offline batch inference for backfill and warm start caching, lowering average cold user initialization time from 3s to 1.1s.
- Partnered with data engineers to define feature freshness SLAs and Kafka stream versioning for consistency across training and serving.
Big Data Streaming & Processing
- Assembled an Apache Flume service on a private cloud infrastructure to ingest100+TB/day log files from cloud computing applications and dispatch tagged log events to downstream services all in real-time
- Used Kafka as a primary data storage solution to hold short term log data reducing data retrieval latency from 3s to 0.5s
- Used Hadoop Distributed File System as a secondary data storage solution to persist PB-level historical log data
- Built an alerting module using Spark Streaming to catch error logs from Kafka and notify the internal management system of cloud computing applications achieving a total latency of less than ls
- Built an analysis module using Spark Streaming to consume and aggregate log data based on severity levels and generate health reports of all cloud computing applications on a daily basis, improving 5x efficiency.
Customer Lifetime Value (CLV) Modeling for Retail Finance Division
- Built predictive CLV model using customer transactions, credit performance, engagement behavior, and acquisition cost.
- Utilized XGBoost with feature importance to identify key drivers of long-term customer value.
- Validated model accuracy through holdout testing and adjusted thresholds based on ROI sensitivity.
- Integrated CLV outputs into Tableau to enable Marketing and Finance to track value creation across campaigns.
- Led to a retargeting strategy based on the findings that improved retention among top 20% of customers by 11%.
- Collaborated with CRM and analytics teams to integrate scoring into campaign automation systems.
Real-Time Collaboration Platform
- Developed and managed the backend for a Real-Time Collaboration Platform to support document sharing, task management, and team messaging. Crafted 20+ RESTful APIs for features such as user management, workspace creation, and real-time task updates using Spring Boot.
- Deployed the application on Amazon ECS with auto-scaling capabilities to efficiently handle varying user loads, maintaining high availability during peak usage.
- Integrated PostgreSQL for relational data storage, Amazon S3 for secure document storage, and Amazon ElastiCache (Redis) to reduce data retrieval latency by 40.2% and enhance platform responsiveness.
- Improved service observability and security by implementing aspect-oriented programming (AOP) for real-time metrics emission to Amazon CloudWatch, along with unified authentication and role-based access control to safeguard sensitive data.
- Designed a serverless architecture on Amazon Lambda for real-time task notifications, leveraging Amazon API Gateway WebSocket API, SNS, SQS, and DynamoDB for low-latency message delivery and fault-tolerant workflows. Achieved 35% faster notification delivery compared to traditional polling mechanisms.
- Optimized backend performance with advanced techniques, including connection pooling, query optimization, and data caching, reducing API response times by 32.7% and supporting 3.5x higher concurrent user capacity.
- Ensured high code quality by implementing unit and integration tests with JUnit, Mockito, and Spring MockMVC, achieving 85%+ test coverage, which significantly reduced production bugs by 40%.
- Automated continuous integration and deployment pipelines using GitHub Actions, Amazon CodeDeploy, and Amazon CodePipeline, reducing deployment times by 42.5% and ensuring minimal downtime during releases.
- Actively engaged in project prototyping, provided technical guidance, and conducted peer code reviews, fostering a collaborative development environment and improving team productivity by 20%.
Simultaneous Localization and Mapping (SLAM) Optimization in Indoor Robotics
- Enhanced a real-time SLAM module for autonomous indoor robots using LiDAR + IMU + monocular RGB input, deployed in warehouse navigation systems.
- Replaced traditional EKF-based pose estimation with graph-based optimization (g2o) and iSAM2, improving localization stability in dynamic environments.
- Integrated deep loop closure detection using NetVLAD + SuperPoint descriptors, achieving 4.7% lower absolute trajectory error in TUM-RGBD dataset.
- Parallelized scan matching and pose graph updates using CUDA kernels, reducing update latency by 35% under heavy mapping loads.
- Deployed map serialization module using OctoMap and ROSbag, enabling efficient map storage and multi-session merging.
- Incorporated uncertainty-aware path planning using Bayesian occupancy grids, improving collision avoidance success rate from 82% → 94%.
- System supported in production with 20+ mobile units, reducing human intervention in warehouse restocking by ~2.6 hours/day per location.
NLP & Deep Learning, Text Understanding
- Established an NLP system to summarize the text through TensorFlow in the environment built by Nvidia Docker.
- Analyzed and processed 2TB text summarization datasets from THUCnews. LCSTS.CSL news headlinescontexts and judicial summaries by NLTK
- Benchmarked the performance of Point-Generator, WoBERT, Nezha, and T5 on the above datasets to obtain proper title/ abstract, guideline and summaries.
- Applied BERT WoBERT to improve prediction accuracy by 5.6% and 4.5% respectively
- Expedited the inference of these transformer-based models by1.55xfaster via Turbo Transformer
- Accelerated the modeling run-time performance by 8xwith parallel computation using CUDA based on GPUs.
- Applied the Bert-of-Theseus method to distill WoBERT shrank model size to 50%.
一线大厂导师亲自带队 做真正有价值的实战项目
更多定制化实习项目欢迎咨询
不是所有项目都值得做,我们帮你定制一段只属于你的项目经历
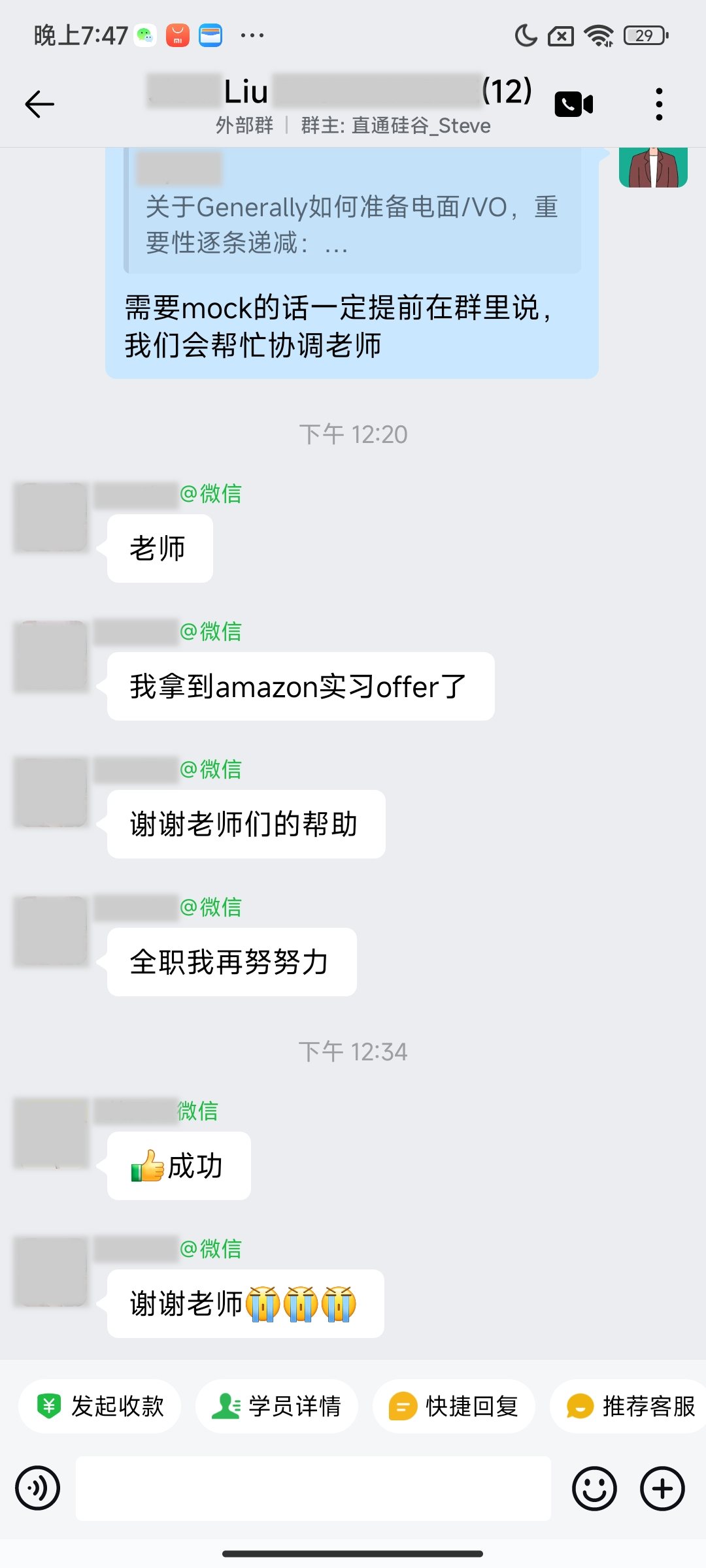
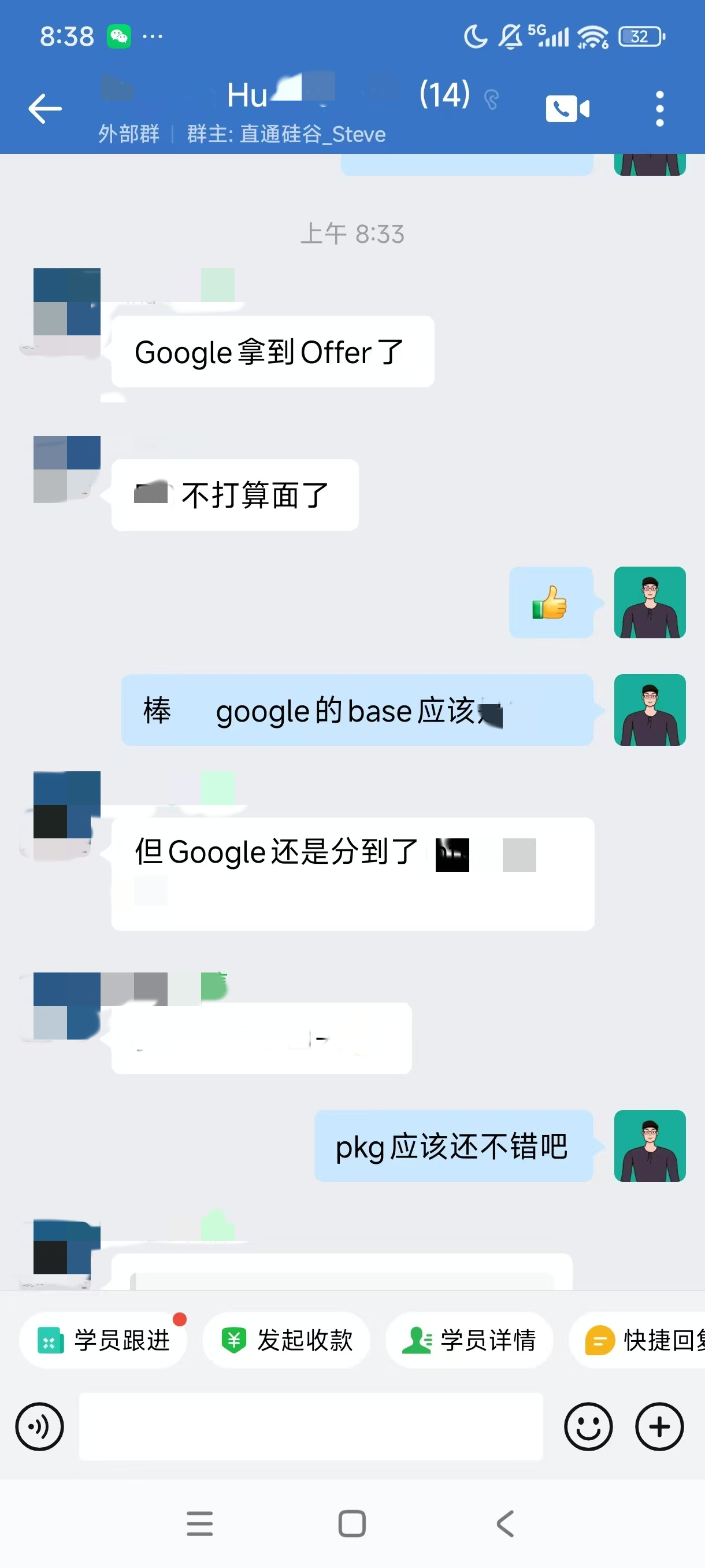
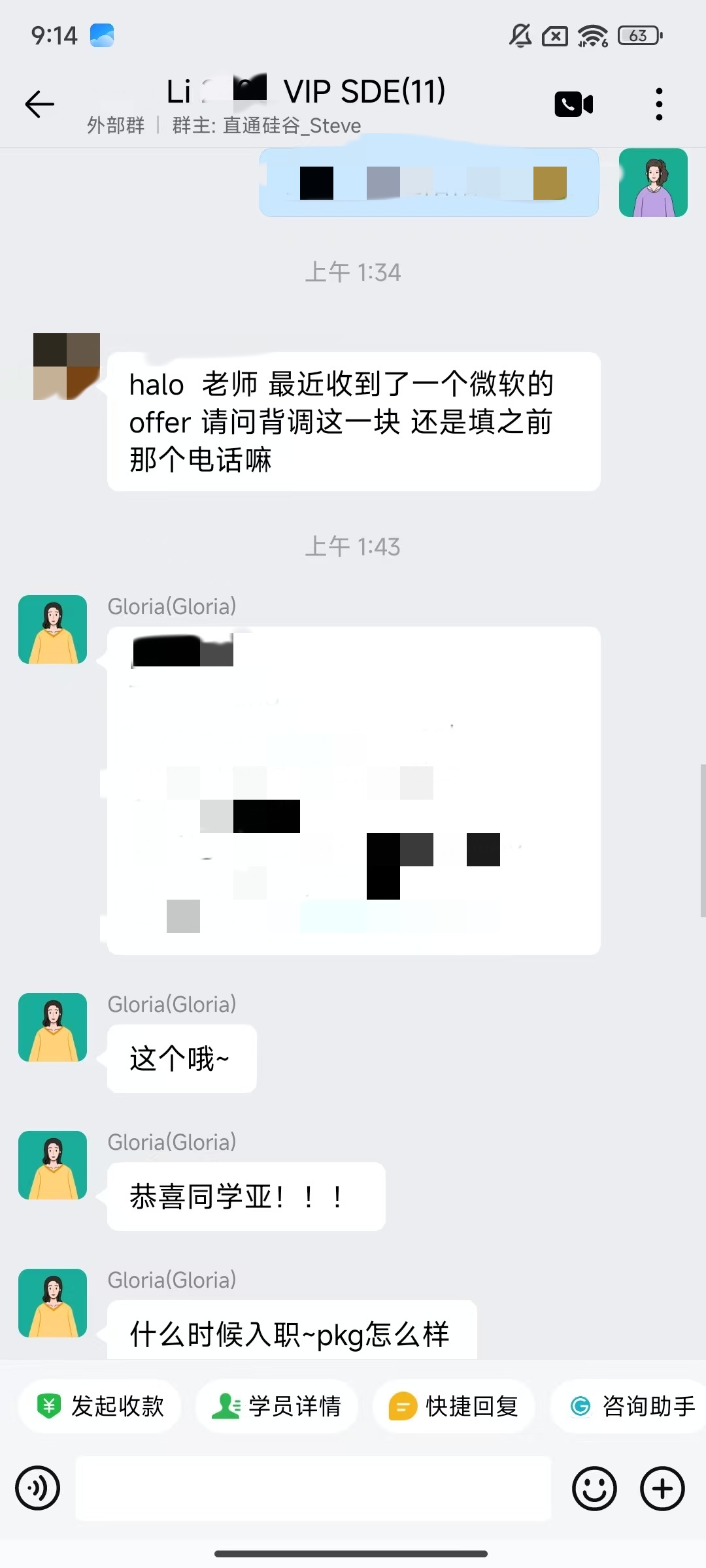
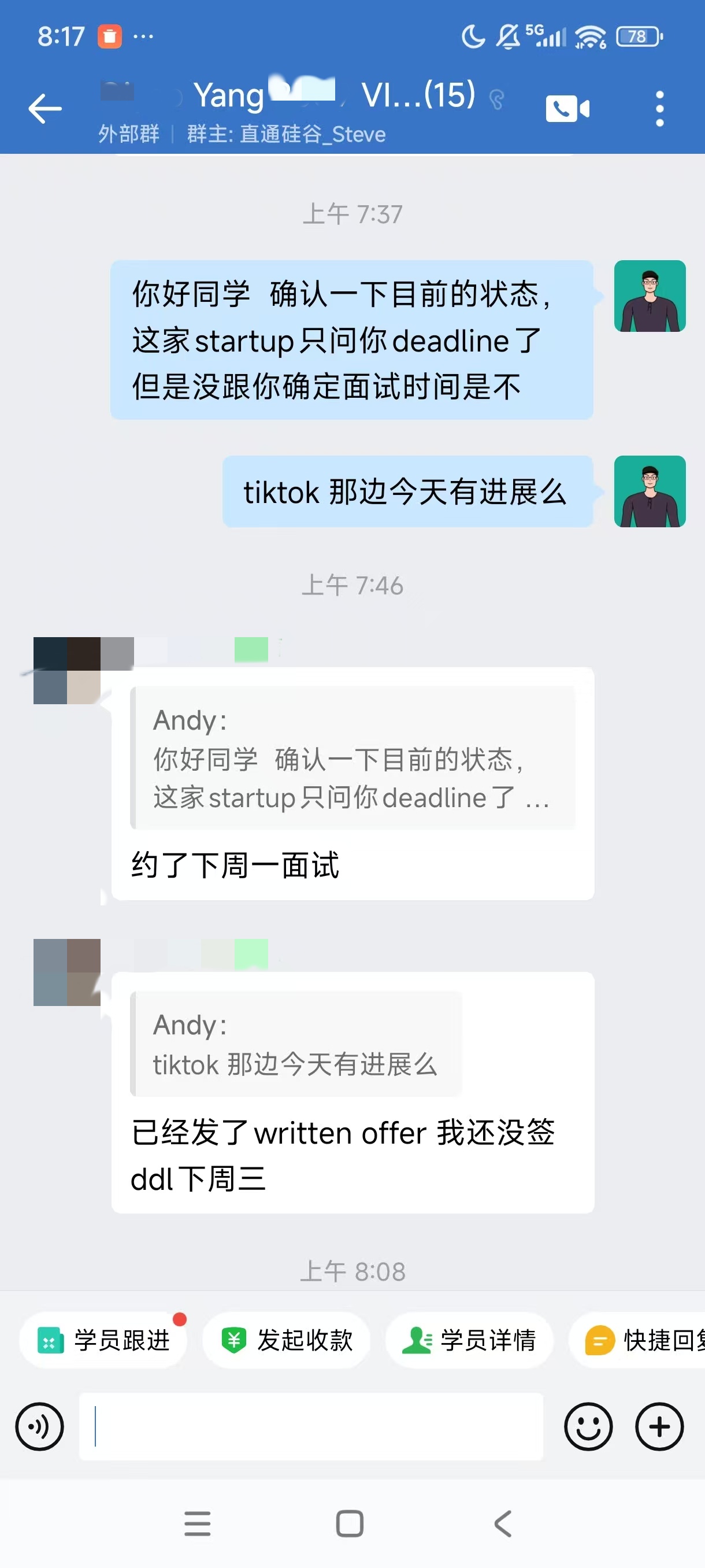
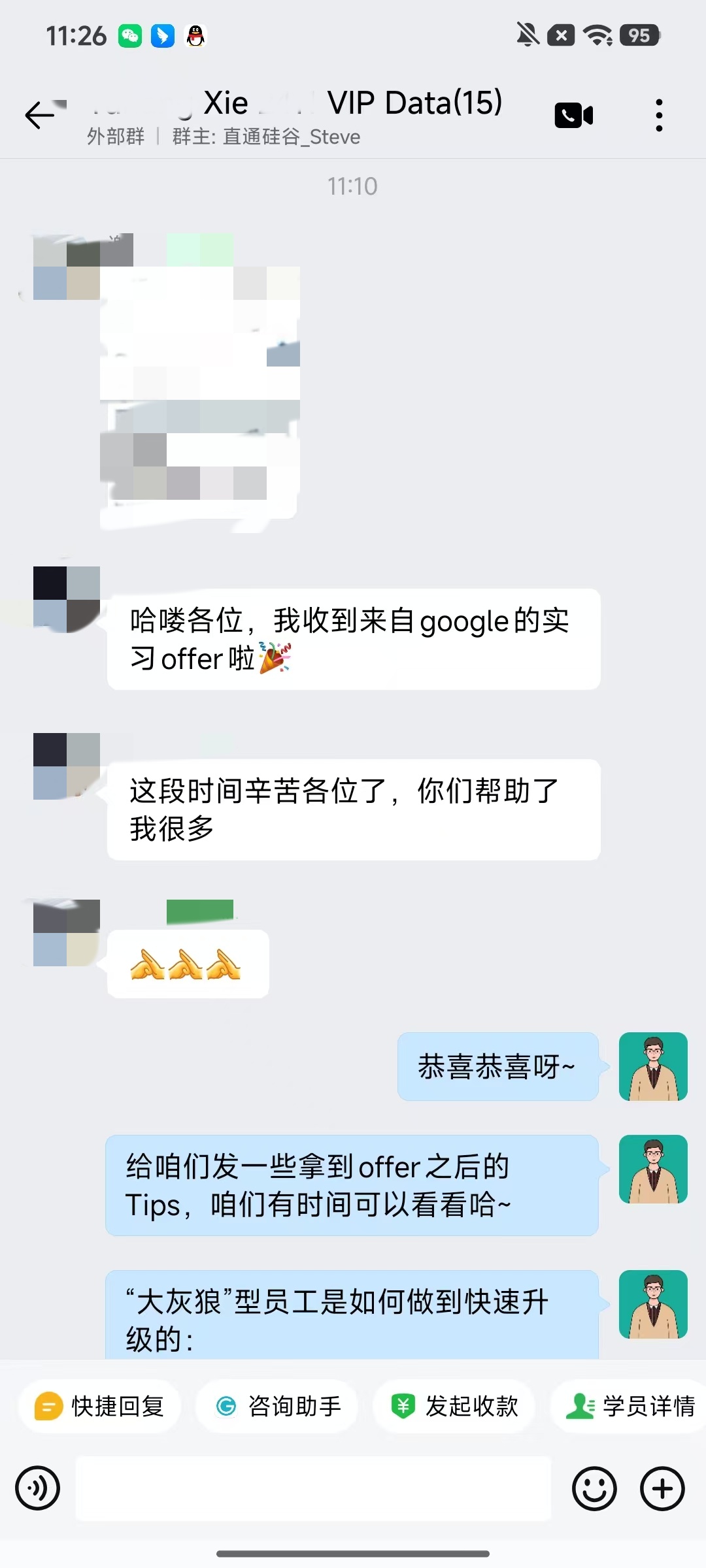
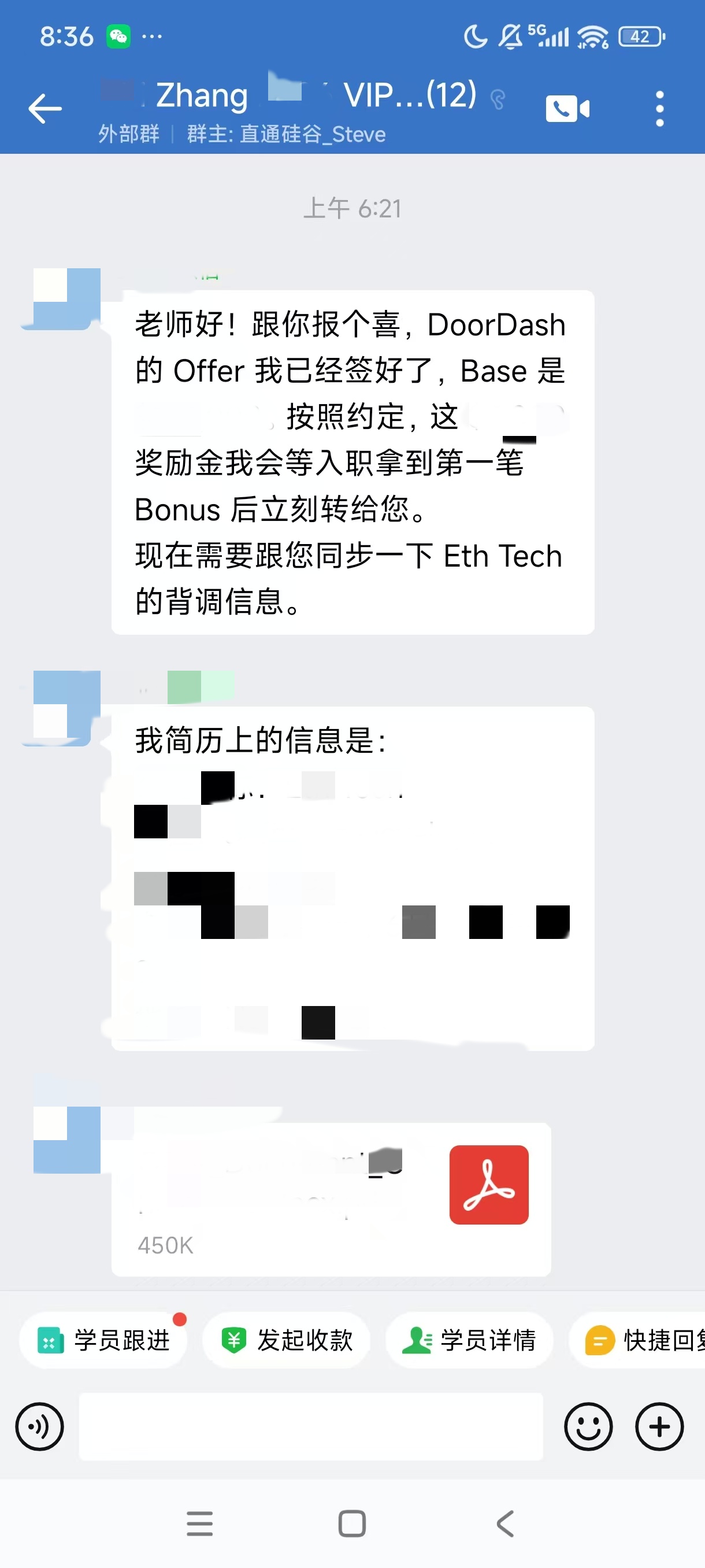
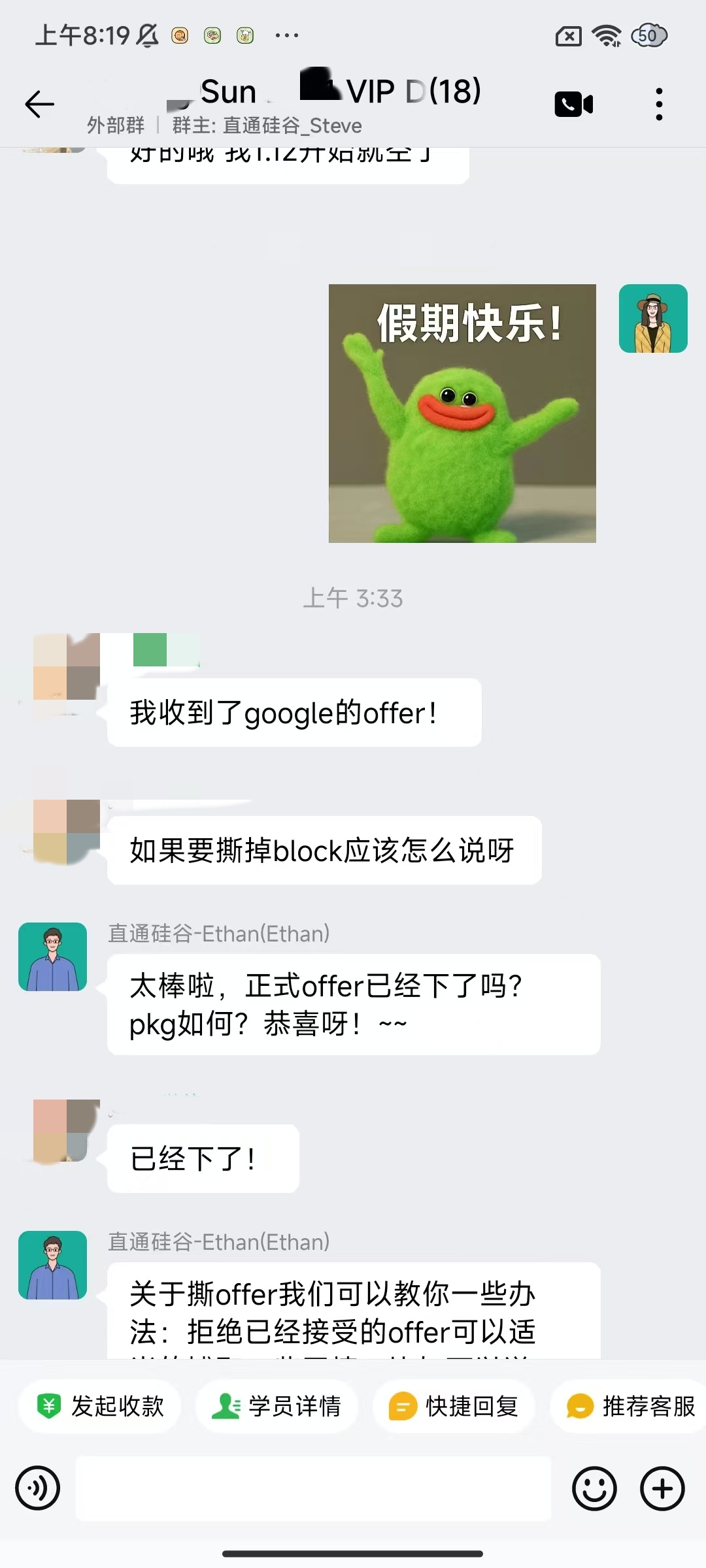
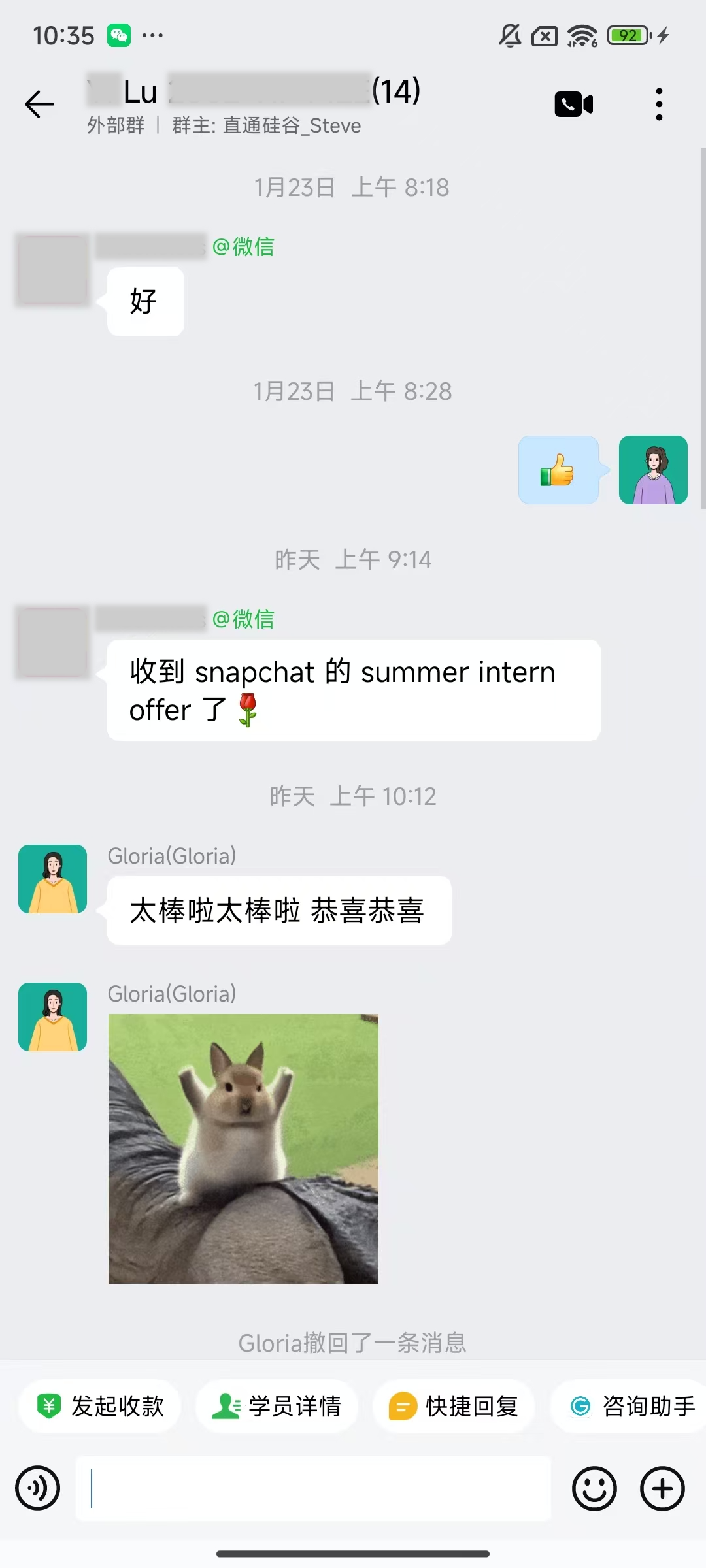
大厂Offer上岸捷报
每份Offer都是工程思维解决真实问题的证明
导师不仅教技术,更教你
怎么把项目写进简历、怎么讲给面试官听
但准备得再好和高压下能答对是两码事
我们加入真实还原模拟面试环节——提前演练各种状况
- •由目标方向的大厂在职面试官1V1带练
- •全程按真实公司的提问逻辑和考察重点
- •从行为问题到技术深挖,甚至突发状况都演练到位
提前排查卡点,演练深度追问细节,避开隐形扣分项——
正式面试时,才能稳定发挥不踩坑
面试前Mock + 扣分项排查
同方向大厂在职面试官带你全流程模拟,提前暴露隐形扣分项
让Deep Dive成为你加分项
教你用清晰逻辑回答技术深挖问题,每句话都落在考察点上
面试复盘 + 认知补漏
不是你答得差,而是踩了面试官眼中的隐形坑;我们带你一一避开
导师帮你打磨面试回答逻辑,试一次真实Mock,就知道该怎么讲了
1300+在职面试官
你的导师也许就是你未来的面试官

Brian
AI工程师

Emily
语音算法工程师

Vivian
软件工程师

Kevin
软件工程师

David
大数据工程师

Alice
UI/UX设计师

James
量化分析师
更多导师资源...
此处仅为部分导师介绍
导师来自你目标岗位方向,懂JD、懂面试、更懂怎么帮你拿Offer